Logging infrastructure¶
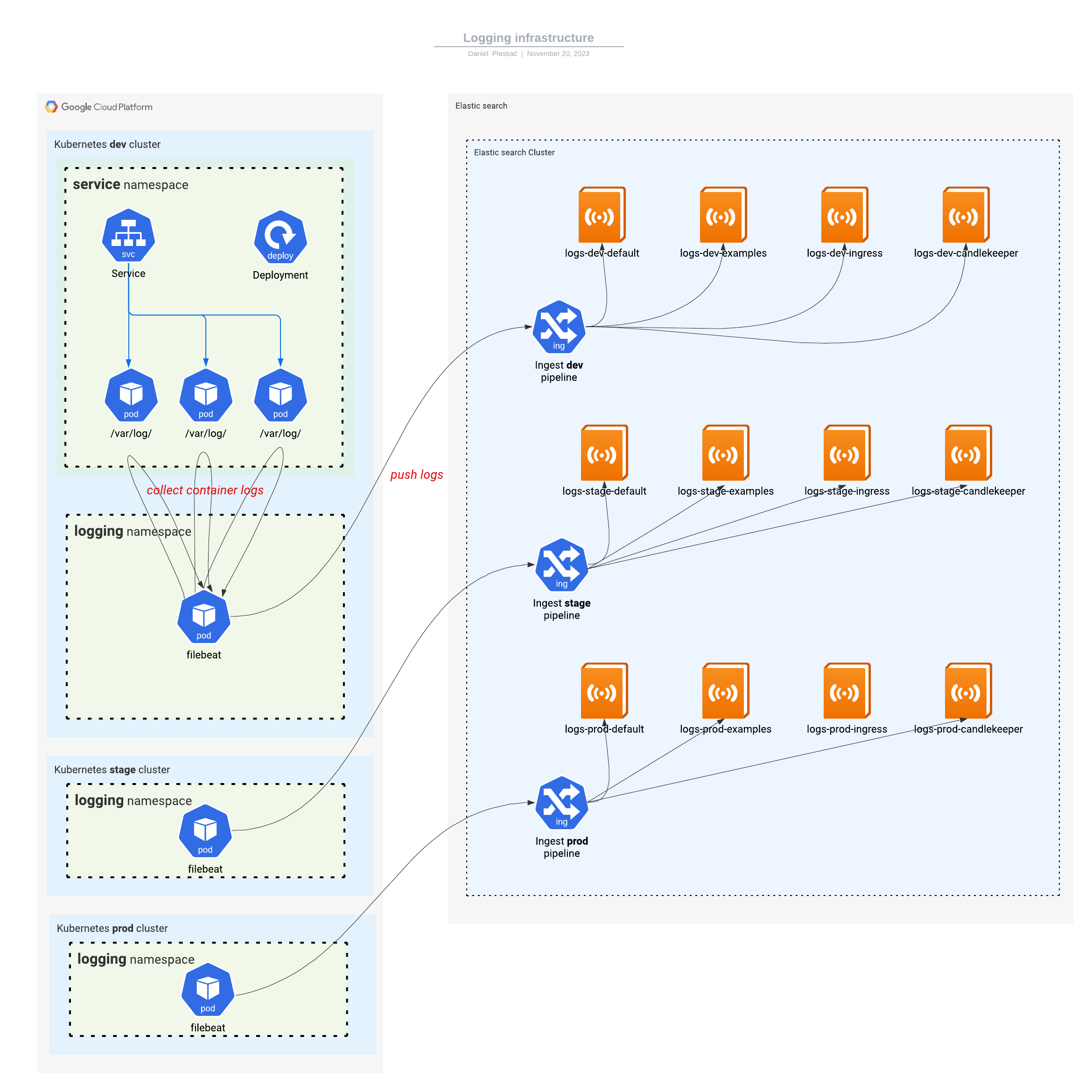
Logging runs on an elastic search technology stack. Each kubernetes cluster hosts a logging namespace which runs eck-operator installed by a helm chart.
Beat CRD manifest is used to install filebeat daemonset. filebeat pods collect logs from services and push them to elastic search's ingest pipeline.
The ingest pipeline demultiplexes the logs into appropriate datastreams. There are multiple datastreams with their own lifecycle policies associated. There is always one default datastream present for each environment logs-<environment>-default, but others can be configured to separate log traffic, for example logs-dev-examples, logs-dev-ingress, logs-dev-candlekeeper, etc.
Links¶
Source code * operator * filebeat * datastreams
Elastic credentials
* tf-runner-<environment> users were created manually with passwords stored in secret manager as do-logging-<environment>-key. These are used by terraform/terragrunt to create elastic resources.
* filebeat-<environment> api keys are created by terraform and give filebeat access to ingest pipelines.
* log_viewer role is mapped to SSO google_users